
Après le premier article dédié à la présentation du projet Univers, et l’article précédent dédié à l’apprentissage non-supervisé, ce nouvel article va proposer une autre façon de produire de l’analyse sémantique, jusqu’à améliorer les résultats obtenus, via l’apprentissage supervisé.
« Une seconde. De l’apprentissage supervisé, sans donnée annotée ? »
Voyons ce qu’il en est en rappelant d’abord l’état de notre réflexion à l’issue du dernier article !
Dans l’épisode précédent…
La donnée d’entrée du projet était un ensemble de nuages de points 3D non labellisés. Le but était de caractériser automatiquement la nature des surfaces représentées, en distinguant a minima végétation, falaise et éboulis.
Nous avons calculé les propriétés de chaque point en nous focalisant sur leurs voisinages locaux. Par la suite, l’algorithme des k-means a permis d’aboutir à des résultats de classifications relativement satisfaisants, dès lors que l’ambition initiale était modérée (tant pour le nombre de classes, que pour la taille et la résolution du jeux de données).
La question centrale à ce stade de notre réflexion est : « comment être plus ambitieux? » Comment produire des résultats de meilleure qualité ?
Extraction d’échantillons annotés
Sans surprise, la réponse est…qu’il faut mettre les mains dans le cambouis !
En sachant que les nuages de points 3D utilisés représentent des environnements naturels et que les types de surface à identifier peuvent être reconnues avec une expertise métier limitée (tant qu’on n’a pas à reconnaître les types de roches ou les espèces végétales), l’extraction d’échantillons annotés est relativement peu chère.
CloudCompare
CloudCompare est un logiciel Open Source pour la visualisation de jeux de données 3D. Cet outil est utilisé quotidiennement par les ingénieurs de Géolithe.
L’animation suivante montre qu’on peut extraire une zone à partir de nos nuages de points, à l’aide d’outil de dessin propre à CloudCompare. La clef, ici, est de sélectionner une zone dont on connaît par hypothèse la nature, par exemple une zone de végétation. Ainsi, tous les points du sous-échantillon seront étiquetés comme des points de végétation par la suite.
Analyse des features géométriques en fonction de la classe sémantique
À ce stade de l’analyse, nous avons un ensemble de nuages de points 3D non annotés, et de nouveaux sous-échantillons pour chaque classe sémantique à considérer. Il devient possible d’étudier les features géométriques (telles que définies dans l’article précédent) en fonction des types de surface.
La figure suivante propose deux exemples de feature géométrique, pour un ensemble de tailles de voisinage, et pour trois types de surface différents, à partir de points appartenant à des sous-échantillons extraits à partir de CloudCompare :
- La densité 3D, qui correspond au nombre de points présents dans un espace de 1m³ autour du point de référence. Ici, la densité croît avec la taille du voisinage (nous avons ici des voisinages plus petits qu’1m³, contenant peu de points). La différence due au type de surface est plus intéressante : elle est nette entre la végétation et les autres classes.
- Le coefficient de verticalité, calculé comme le complémentaire sur l’intervalle
[0, 1]de la troisième composante du vecteur normal (directement donné par l’analyse en composantes principales). Trois phénomènes distincts sont observables pour cette variable : (i) le coefficient est élevé pour les falaises, quelle que soit la taille du voisinage, (ii) il décroît rapidement avec l’augmentation de la taille du voisinage pour la végétation, (iii) il est faible et relativement constant pour les éboulis.
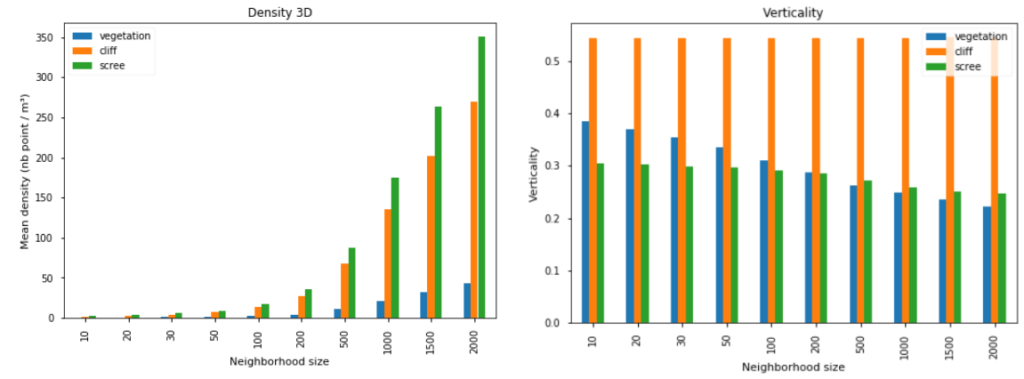
Densité 3D et coefficient de verticalité, en fonction de la taille de voisinage et du type de surface (jeu de donnée « Pombourg »)
Cette approche peut être généralisée à toutes les features géométriques, et pour d’autres classes sémantiques. Tout cela permettant de poser des bases vers l’application d’un algorithme d’apprentissage supervisé.
Entraînement d’un modèle de classification
Plutôt que de proposer une comparaison entre plusieurs algorithmes supervisés, cette section est plutôt l’occasion de comparer une approche supervisée avec une approche non-supervisée (voir article précédent). L’algorithme choisi ici est la régression logistique.
Corrélations entre variables ?
La pertinence de notre ensemble de variables pour appliquer une régression logistique peut être mesurée par le niveau des corrélations existant entre elles. La matrice de corrélation ci-dessous illustre ces liens entre les variables :
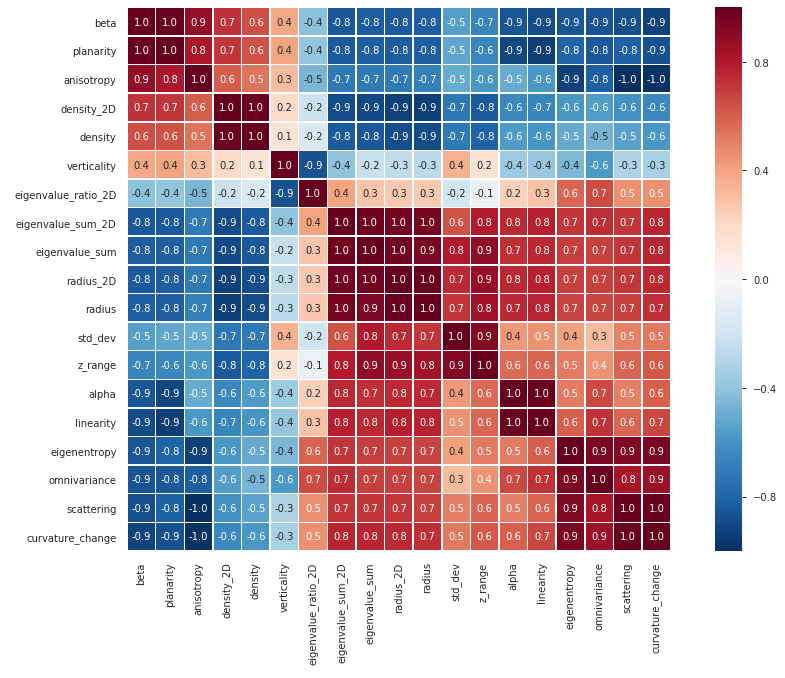
Matrice de corrélation entre les variables (jeu de données « Pombourg », 1000 voisins)
Nous avons ainsi 19 variables (pour une taille de voisinage donnée), parmi lesquelles certaines sont très corrélées. Dans un tel contexte, la régression logistique sera perturbée, réduire la redondance de l’information devient un préalable nécessaire. À titre d’exemple, ici, considérer seulement les variables alpha, anisotropy, verticality and radius permet de construire un modèle plus simple moins pollué par le phénomène de colinéarité.
Par ailleurs, l’analyse pourrait être enrichie via l’adjonction de tailles de voisinage supplémentaire (et le filtrage des variables colinéaires subséquentes).
En route vers la prédiction!
Pour constituer le jeu d’entraînement, la procédure d’échantillon manuelle par CloudCompare a été appliquée à 10 nuages de points, jusqu’à donner 28 échantillons annotés, selon 6 classes. La répartition est la suivante :
| Classe | Nombre d’échantillons | Nombre de points |
|---|---|---|
| Végétation | 10 | 1281k |
| Falaise | 9 | 865k |
| Éboulis | 4 | 143k |
| Route | 2 | 36k |
| Béton | 2 | 155k |
| Sol | 1 | 71k |
À partir de ces points, des jeux d’entraînement et de test sont constitués (resp. 75% et 25% des points), pour valider les résultats de classification. On obtient 97.2% de précision (« accuracy« ), sans vrai effort d’optimisation de l’ensemble des variables (toutes les variables, voisinages de 20, 200, 1000 et 2000 points). La matrice de confusion associée est proposée ci-après :
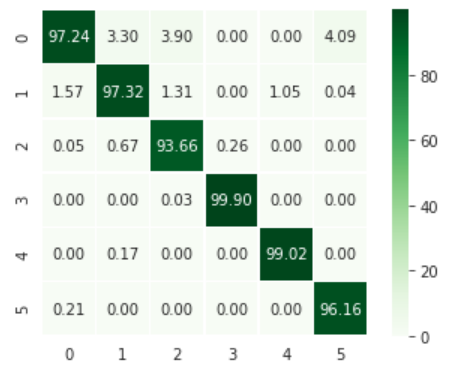
Matrice de confusion (0: végétation, 1: falaise, 2: éboulis, 3: route, 4: béton, 5: sol), valeur indiquée en %
Il est également possible d’observer les résultats de classification visuellement sur un sous-ensemble de nuages de points :

Résultats de classification (vert: végétation, gris: falaise, marron: éboulis, bleu: route, orange: béton)
Même s’il y a quelques zones mal identifiées, le résultat d’ensemble paraît pertinent ! Et il reste des axes d’amélioration notables : optimiser l’ensemble des variables, produire plus de sous-échantillons annotés, améliorer la représentativité des données annotées, post-traiter les résultats pour lisser les frontières entre les classes, …
Vers la weak supervision
Pour clore le chapitre de la segmentation sémantique de points 3D, un algorithme innovant a retenu notre attention, à savoir la weak supervision, ou « comment utiliser une méthode de deep learning sans donnée annotée (mais avec une forte expertise métier)« .
Cette méthode a été introduite par des chercheurs de Stanford, et a abouti à des publications scientifiques ainsi qu’au développement d’un framework Open Source, Snorkel. La figure ci-dessous montre le processus d’ensemble derrière
cette méthode, de l’expertise métier (définition de « fonction de labellisation ») jusqu’à la construction d’un modèle prédictif.
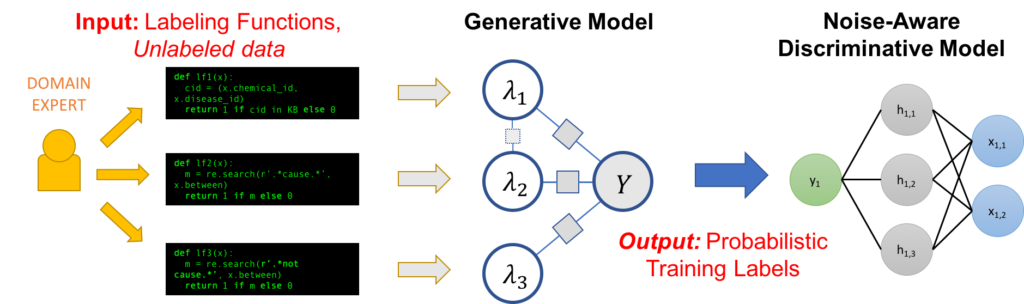
Schéma de la procédure de weak supervision, d’après Snorkel
Dans le cadre du projet Univers, c’est encore un travail en cours. Ceci étant, nous avons déjà des résultats encourageants, grâce à l’appui des équipes de Géolithe, qui nous fournissent ici l’expertise métier nécessaire à la définition des fonctions de labellisation.
Cette méthode est prometteuse dans le contexte de l’analyse automatique des surfaces en contexte naturel, en tout cas cela va constituer un cas d’étude fascinant dans les prochains mois !
Conclusion
Pour conclure cette série d’article dédiée au challenge Univers, et à notre collaboration avec Géolithe, nous pouvons avancer qu’il est possible de construire des prototypes d’algorithme d’apprentissage supervisé même sans donnée annotée en entrée.
Même en étant aussi concis que possible, des aspects intéressants de ce travail n’auront pas été abordés (e.g. la performance au regard du temps de calcul).
Si vous désirez de plus amples informations, n’hésitez pas à commentaire cet article, à consulter le code récemment publié sur Github et à y contribuer ! Et si vous êtes intéressés pour collaborer avec Oslandia sur ce type de problématique, infos@oslandia.com est là pour vous !

