At Oslandia, we like working with Open Source tool projects and handling Open (geospatial) Data. In this article series, we will play with the OpenStreetMap (OSM) map and subsequent data. Here comes the first article of this series, dedicated to the presentation of our working framework.
Python is your friend, Luigi your plumber
In this project, we have used our favourite data handling tool, namely Python with its pandas and numpy packages. That is quite sufficient to download and manage data sets in a Python framework, however we still misses a methodology layer!
In this way, we will use Luigi, which is another Python package dedicated to the job pipeline building. As we can read in the Luigi documentation, this tool allows us to manage every tasks and organize them compared to each other, by clarifying the dependencies.
A quick benchmark about existing Luigi utilizations shows that machine learning applications are extremely compatible with this package. That is particularly true if we consider Map/Reduce frameworks. Here we will demonstrate that Luigi keeps its interest in our case, with a slightly different usage.
What are the main tasks in our workflow?
We organize the analysis of OSM data quality in three main task categories, that we will describe as follows. Some of these tasks will be developped in subsequent blog articles.
OSM Data Parsing
The first task of the data analysis is the parsing process. We start from files in a typical OpenStreetMap file format, with the .pbf extension. After this step we obtain classic .csv files, considering that we might have in-base data as well.
Here are some examples of Luigi tasks:
– parse the OSM entities (nodes, ways, relations)
– parse the OSM tags (keys and values)
– parse the OSM users directly from the contributions
OSM Metadata Building
If we focus on the first previous example, the OSM entity parsing, we get the history of each OSM elements. These elements are nodes, characterized by geographical coordinates (lat,lon), ways, characterized by a set of nodes, and relations, characterized a set of members (members being nodes, ways and others relations).
Each of these elements are created (that’s quite obvious!), and may be modified or even deleted in the OSM API. These modifications are done within change sets by OSM contributors. We then may identify typical Luigi tasks :
– extract the OSM element metadata (date of creation, number of versions…)
– extract the OSM changeset metadata (timestamps, number of done modifications…)
– extract the OSM user metadata (timestamps, number of opened change sets,
number of modifications…)
OSM Metadata Analysis
A last major part of the analysis concerns the metadata analysis: these data are extremely useful in the quality evaluation: we hypothesize that knowing the way each user contributes to the API gives an information on its ability to do it properly. In the end, knowing that expert users have contributed to an element will let us think that this element is of good quality.
Here we develop a more machine-learning-focused framework to exploit the data, as illustrated by the following tasks:
– prepare the data
– reduce dimensionality through a Principle Component Analysis
– classify the users with the help of the k-means algorithm
Outline of the project: characterize OSM data quality
To summarize all these points, we have designed a complete framework and made it effective by the way of the Luigi package. It can be illustrate by the following figure, obtained with the help of the Luigi daemon, which permits to explore the task pipeline graphically as well as to explore their accomplishment degree while running.
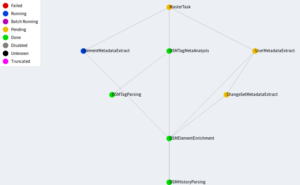
Example of Luigi dependency graph
We can identify some of previously mentionned tasks in this graph:
– OSMHistoryParsing and OSMTagParsing are sources, these tasks provide initial data sets by using pyosmium capacities.
– OSMElementEnrichment is an intermediary task in which additional features are merged to OSM history data
– These additional features are used in every subsequent tasks: OSMTagMetaAnalysis, ElementMetadataExtract, ChangeSetMetadataExtract and UserMetadataExtract. The former task ends tag analysis, while the latter ones generate metadata from OSM history.
– MasterTask is an abstract task that yields each final tasks. Its completion equals to the success of the pipelined procedure.
In this example we do not have put other tasks in the pipeline (e.g. machine learning procedures), however they can be integrated in the framework with a minimal effort.
Conclusion
Here we have described how we plan to analyze the OSM data and how to assess its quality. Even if other choices exist (we still have choice!) we use Python and its powerful available package set. Amongst these packages Luigi has a clear interest.
In the next article, we will address the geospatial quality definition. Subsequent articles will be focused on the alysis, until characterizing OSM data quality.

